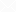客服微信

本文为云贝教育 刘峰 原创,请尊重知识产权,转发请注明出处,不接受任何抄袭、演绎和未经注明出处的转载。
PostgreSQL多元统计信息
1. 常见值(Common Values):列中出现频率较高的具体数值或离散值。这些值被记录在统计信息中,每个值对应一个条目。
2. 频率(Frequencies):与每个常见值相对应的出现次数或占比。这些数据提供了常见值在列中出现的相对频繁程度,有助于量化其代表性。
PostgreSQL的统计信息收集机制会定期(或在特定触发条件下)对表进行分析,以更新MCV等统计信息。对于某列,系统会选择一定数量(默认为100个)的最常见值以及它们对应的频率进行记录。选择的标准通常是基于这些值在数据集中的相对频率,确保所选值能够代表大部分数据。MCV信息在查询优化过程中的作用主要体现在以下几个方面:
1. 查询代价估算
查询优化器在规划查询执行计划时,需要对不同操作(如索引扫描、全表扫描、连接操作等)的代价进行估算。MCV信息可以帮助优化器更准确地估计基于特定条件筛选数据时可能返回的行数。例如,对于一个带有WHERE子句的查询,如果条件涉及到的列有MCV信息,优化器可以根据筛选值在MCV列表中的频率来近似计算满足条件的行数,从而更好地判断是否应该使用索引或进行全表扫描。
2. 索引选择与利用率
MCV信息对索引选择有直接影响。当查询条件中的值属于MCV集合时,优化器更倾向于选择相关的索引来加速查询,因为这些值在数据中较为普遍,索引扫描很可能带来显著的性能提升。反之,如果查询条件中的值在MCV中未出现或出现频率极低,优化器可能会认为全表扫描更为高效,因为索引在这种情况下可能覆盖的数据比例较小。
3. 数据分布假设验证
MCV信息还能帮助优化器验证或修正对数据分布的假设。在缺乏精确统计信息的情况下,优化器可能需要基于某些通用假设(如均匀分布)来估算查询成本。然而,实际数据往往具有特定的模式和偏斜,MCV信息能揭示这种非均匀性,使优化器能够做出更符合实际情况的决策。
1. 查询性能优化
对于包含大量数据且查询条件频繁涉及特定列的应用场景,MCV信息的价值尤为突出。例如,在电商系统中,商品分类、品牌等字段可能存在明显的热点值,查询时经常按照这些字段进行过滤。通过维护MCV信息,优化器可以更准确地预估查询结果集大小,合理选择索引,从而提高查询响应速度。
2. 统计信息维护策略
为了确保MCV信息的有效性,应定期更新统计信息,或者在数据发生显著变化后手动触发更新。可以使用ANALYZE命令对单个表或整个数据库进行分析。对于动态更新频繁的表,可以考虑设置更短的统计信息自动更新周期,确保MCV信息紧跟数据变化趋势。
3. 调优案例分析
在进行查询性能调优时,可以通过检查查询计划(使用EXPLAIN或EXPLAIN ANALYZE命令)来观察MCV信息是否被有效利用。如果发现查询计划选择不当,可以对比实际数据分布与MCV信息,检查是否存在统计信息过时、不准确或未被充分利用的情况,据此调整查询语句、索引结构或统计信息更新策略。
4.1 功能依赖

规划器可以使用从 pg_class 获得的页数和行数来确定 t 的基数:

数据分布非常简单;每列中只有 100 个不同的值,均匀分布。
以下示例显示了估计 a 列上的 WHERE 条件的结果:

规划者单独估计每个条件的选择性,得到与上述相同的 1%估计值。然后它假设条件是独立的,因此将它们的选择性相乘,产生仅为 0.01% 的最终选择性估计。这是一个严重的低估,因为匹配条件 (100) 的实际行数要高出两个数量级。
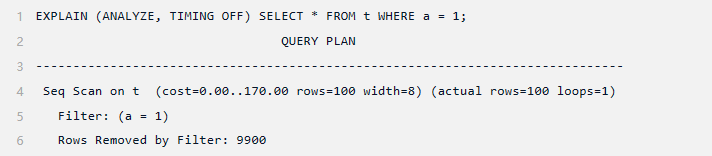
这个问题可以通过创建一个统计对象来解决,该对象指示 ANALYZE 计算两列上的函数依赖多元统计信息:
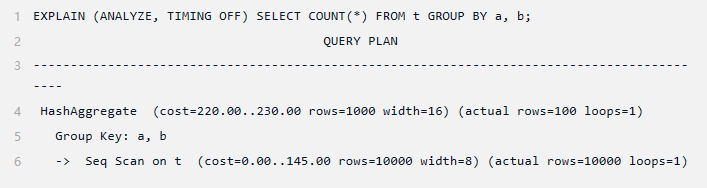
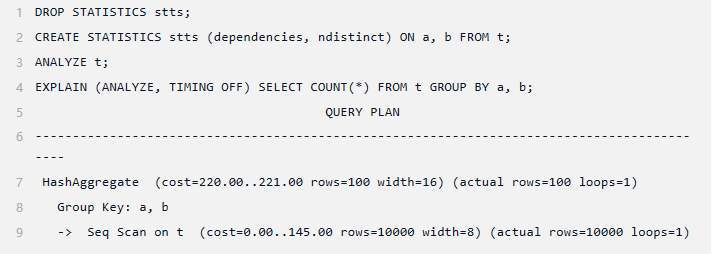
函数依赖是非常廉价且高效的统计类型,但它们的主要限制是其全局性(仅跟踪列级别的依赖关系,而不是各个列值之间的依赖关系)。
本节介绍 MCV(最常见值)列表的多变量变体,这是每列统计信息的直接扩展。这些统计数据通过存储单个值来解决这一限制,但无论是在分析中构建统计数据、存储还是规划时间方面,它的成本自然都更高。
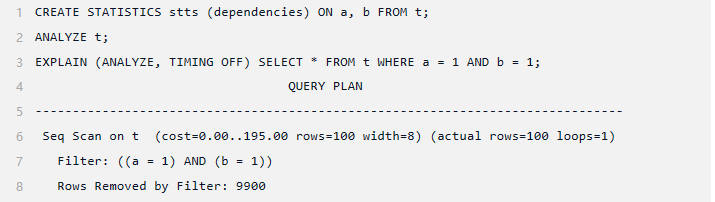
让我们再次查看3.1的查询,但这次使用在同一列集上创建的 MCV 列表(确保删除函数依赖性,以确保规划器使用新创建的统计信息)。
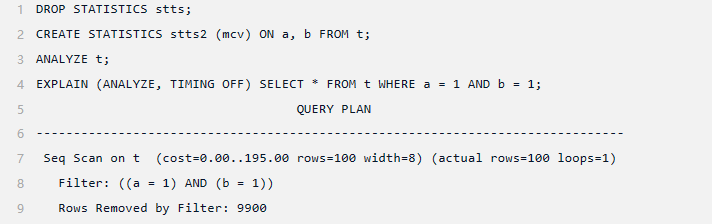
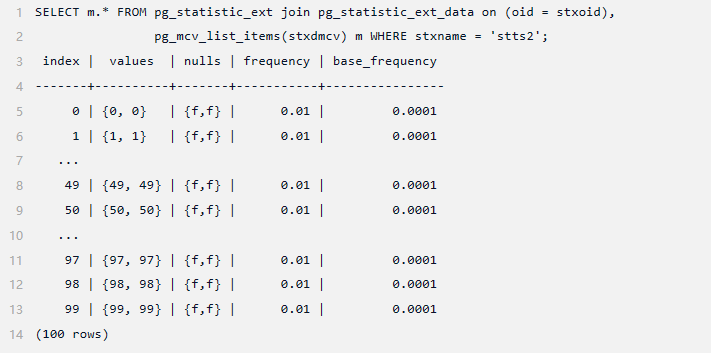
该估计与函数依赖项一样准确,这主要是因为该表相当小,并且分布简单,不同值的数量较少。在查看第二个查询(函数依赖关系处理得不是特别好)之前,让我们先检查一下 MCV 列表。
可以使用 pg_mcv_list_items 设置返回函数检查 MCV 列表。
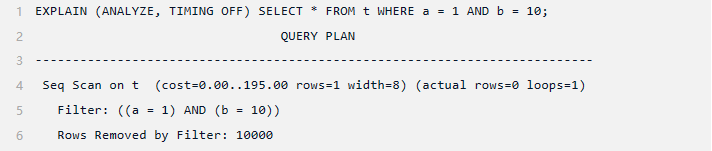
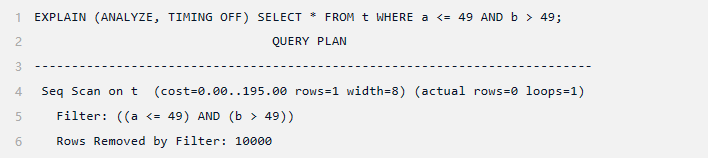
PostgreSQL的多元统计信息(MCV)作为一种重要的数据库内部机制,为查询优化器提供了关于数据列常见值及其频率的关键信息。
通过对MCV的深入理解与有效运用,数据库管理员和应用程序开发者可以显著提升查询性能,确保数据库系统在面对复杂查询和大规模数据时仍能保持高效运作。通过定期更新统计信息、合理设计索引并结合实际业务特点,充分发挥MCV在查询优化中的作用,是构建高性能PostgreSQL数据库应用的关键实践之一。
想了解更多PG相关的学习资料(技术文章和视频),可以微信公众号或B站搜索《云贝教育》,免费获取。
想了解更多PG相关的学习资料(技术文章和视频),可以微信公众号或B站搜索《云贝教育》,免费获取。
想了解更多PG相关的学习资料(技术文章和视频),可以微信公众号或B站搜索《云贝教育》,免费获取。
另外需要学习资料 的同学,可以添加联系方式:(同V) 陈老师 199-4146-4235 / 郑老师 199-0663-2509 / 蕾老师199-0663-5786,我们会持续更新学习视频。