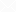客服微信

本文为云贝教育 刘峰 原创,请尊重知识产权,转发请注明出处,不接受任何抄袭、演绎和未经注明出处的转载。
缓冲区管理器管理共享内存和持久存储之间的数据传输 , 它会对 DBMS 的性能产生重大影响。 PostgreSQL 缓冲区管理器工作非常高效。
本章介绍 PostgreSQL 缓冲区管理器。第一部分提供概述 ,后续部分描述以下主题:
· 缓冲区管理器结构
· 缓冲区管理器锁
· 缓冲区管理器的工作原理
· 环形缓冲区
· 脏页的刷新
图1.1 缓冲区管理器、存储和后端进程之间的关系
本节介绍理解后续各节中的描述所必需的关键概念。
PostgreSQL 缓冲区管理器包含缓冲区表、缓冲区描述符和缓冲池 ,这些将在下一节中介绍。缓 冲池层存储数据文件页 ,例如表和索引 ,以及自由空间映射和可见性映射。缓冲池是一个数组, 其中每个槽存储数据文件的一页。缓冲池数组的索引称为 buffer_ids。
在PostgreSQL中 ,所有数据文件的每一页都可以分配一个唯一的标签 ,即缓冲区标签。 当缓冲区管理器收到请求时 , PostgreSQL 使用所需页面的 buffer_tag。
buffer_tag 有五个值:
· specOid :包含目标页的关系所属表空间的OID。
· dbOid :包含目标页面的关系所属数据库的OID。
· rel Number:包含目标页面的关系文件的编号。
· block Num:关系中目标页的块号。
· fork Num:页面所属关系的分叉号。表、自由空间图和可见性图的分叉号分别定义为 0、 1 和 2。
例如 , buffer_tag '{ 16821, 16384, 37721, 0, 7}' 标识位于表的第七个块中的页 ,其 OID 和分 叉号分别为 37721 和 0。该表包含在 OID 为 16384 的数据库中 ,位于 OID 为 16821 的表空 间下。
类似地, buffer_tag“ { 16821, 16384, 37721, 1, 3} ”标识位于自由空间映射的第三块中的页 面 ,其OID和分叉号分别为37721和1。
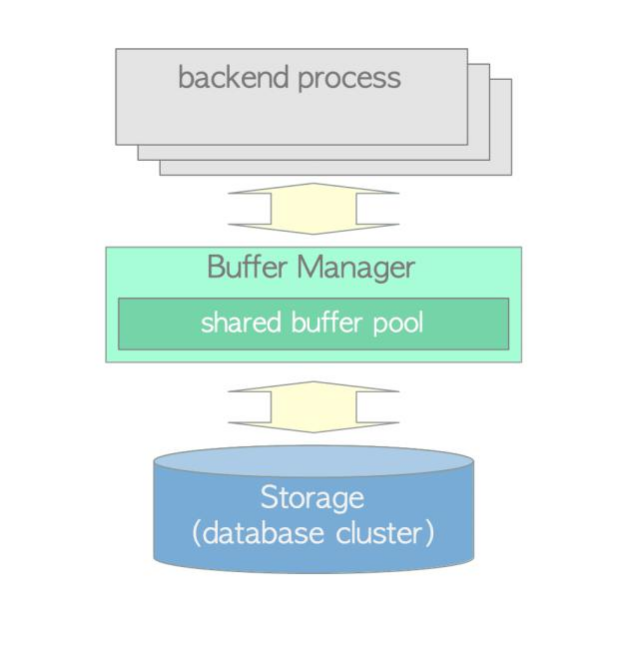
本小节描述后端进程如何从缓冲区管理器读取页面(图 1.2)。
图 1.2 后端如何从缓冲区管理器读取页面
(1) 当读取表或索引页时,后端进程向缓冲区管理器发送包含该页的 buffer_tag 的请求。
(2) 缓冲区管理器返回存储所请求页面的槽的buffer_ID。如果请求的页面未存储在缓冲池中,则缓冲区管理器将该页面从持久存储加载到缓冲池槽之一,然后返回该槽的 buffer_ID。
(3) 后端进程访问buffer_ID的slot(读取所需的页面)。
当后端进程修改缓冲池中的页面(例如 ,通过插入元组)时, 尚未刷新到存储的已修改页面被称为脏页面。
当所有缓冲池槽都被占用并且所请求的页没有被存储时,缓冲管理器必须在缓冲池中选择一页来替换所请求的页。通常,在计算机科学领域,页面选择算法被称为页面替换算法,并且所选择的页面被称为受害者页面。
自计算机科学出现以来,对页面替换算法的研究一直在进行。许多替代算法被提出,PostgreSQL从1. 1版本开始使用时钟扫描算法。 时钟扫描比以前版本中使用的 LRU 算法更简单、更高效。
脏页最终应该被刷新到存储中。但是,缓冲区管理器需要帮助才能执行此任务。在 PostgreSQL 中,两个后台进程(checkpointer 和后台 writer)负责此任务。
关于直接IO
PostgreSQL 版本 15 及更早版本不支持直接 I/O,尽管已经对此进行了讨论。请参阅有关 pgsql-ML的讨论和本文。
在版本 16 中,添加了 debug-io-direct 选项 。该选项供开发人员改进 PostgreSQL 中直接 I/O 的使用。如果开发顺利的话,Direct I/O将在不久的将来正式支持 。
PostgreSQL 缓冲区管理器包含三层:缓冲区表、缓冲区描述符和缓冲池(图 1.3):
图 1.3 缓冲区管理器的三层结构
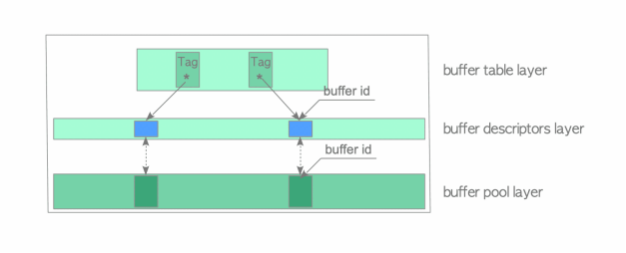
缓冲区表层 :存储存储页的 buffer_tag 与保存存储页各自元数据的描述符的 buffer_ids 之间关系的哈希表。
缓冲区描述符层 :缓冲区描述符数组。每个描述符与缓冲池槽位一一对应 ,并保存对应槽位中所存储页面的元数据。
缓冲池层 :存储数据文件页的数组。数组中的每个槽称为 buffer_ids。
请注意 ,为了方便起见 ,采用术语“缓冲区描述符层 ” ,并且仅在本文档中使用。
这些层将在以下小节中详细描述。
缓冲表在逻辑上可以分为三部分: 哈希函数、 哈希桶槽和数据条目(图1.4)。
内置哈希函数将 buffer_tags 映射到哈希桶槽。即使哈希桶槽位的数量大于缓冲池槽位的数量,也可能会发生冲突。因此,缓冲表使用单独的链接和链表方法来解决冲突。当数据条目映射到同一个桶槽时,该方法将条目存储在同一个链表中,如图1.4所示。
图 1.4 缓冲表。
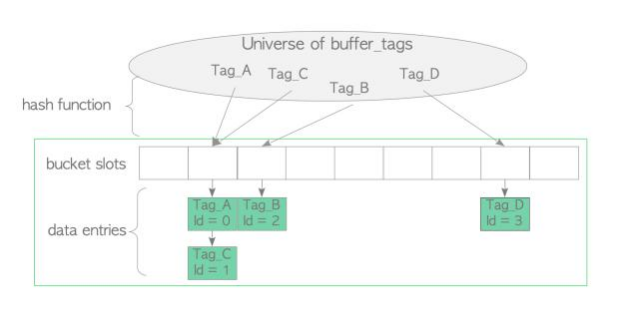
数据条目包含两个值:页面的 buffer_tag 和保存页面元数据的描述符的 buffer_id。例如,数据条目“ Tag_A, id = 1 ”表示buffer_id为1的缓冲区描述符存储用Tag_A标记的页面的元数据。
例如, buffer_tag“ { 16821, 16384, 37721, 1, 3} ”通过hash运算之后bucket slot = 1;而 buffer_tag“ { 16821, 16384, 54784, 0, 13} ”通过hash运算之后bucket slot =3。
缓冲区描述符的结构在 9.6 版本中得到了改进。首先,我解释 9.5 及更早版本中的缓冲区描述符,然后解释 9.6 及更高版本中的缓冲区描述符与以前的版本有何不同。
9.5及更早版本中的缓冲区描述符结构保存了相应缓冲池槽中存储页面的元数据。缓冲区描述符结构由 BufferDesc 结构定义。以下是一些主要字段:
tag保存了相应缓冲池槽中存储页的buffer_tag。 (缓冲区标签在第 1.1.2 节中定义。)
buf_id标识描述符。相当于对应缓冲池槽的buffer_id。
refcount保存当前正在访问关联存储页面的 PostgreSQL 进程数。它也称为引脚数。
◦ 当 PostgreSQL 进程访问存储的页面时,引用计数必须加 1 (refcount++)。访问页面 后,refcount必须减1( refcount--)。
◦ 当引用计数为零时,关联的存储页面将被取消固定,这意味着它当前未被访问。否则,它会被固定。
usage_count保存关联存储页自加载到相应缓冲池槽以来已被访问的次数。 它用于页面替换算法(第 4.4 节)。
content_lock和 io_in_progress_lock是轻量级锁,用于控制对关联存储页面的访问。这些字段在第 3.2 节中描述。
标志可以保存关联存储页面的多种状态。主要状态如下:
· dirty bit表示存储的页是脏的。
· valid bit存储的页是否有效,即可以读取或写入。
◦ 如果该位有效 ,则对应的缓冲池槽存储了一个页面,并且描述符保存了页面元数据,并且可以读取或写入所存储的页面。
◦ 如果该位无效,则描述符不保存任何元数据,并且无法读取或写入存储的页面。
buf_hdr_lock是一个自旋锁,保护以下字段 :flags、 usage_count、 refcount。
freeNext是指向下一个描述符的指针,用于生成空闲列表,这将在下一小节中进行描述。
缓冲区描述符结构由 BufferDesc 结构定义。
tag保存了相应缓冲池槽中存储页的buffer_tag。
· buf_id 标识描述符。
· content_lock 是一个轻量级锁,用于控制对关联存储页面的访问。
· freeNext 是指向下一个描述符的指针,用于生成空闲列表。
· states可以保存关联存储页面的多个状态和变量,例如refcount和usage_count。
flags、usage_count 和 refcount 字段已组合成单个 32 位数据(状态)以使用 CPU 原子操作。 因此,io_in_progress_lock 和自旋锁 (buf_hdr_lock) 已被删除, 因为不再需要保护这些值。
为了简化以下描述 ,定义了三种描述符状态:
Empty:当对应的缓冲池槽没有存储页面时(即refcount和usage_count为0),该描述符的状态为空。
Pinned:当相应的缓冲池槽存储一个页面并且任何 PostgreSQL 进程正在访问该页面时(即 refcount 和 use_count 大于或等于 1),该缓冲区描述符的状态被 pinned。
Unpinned:当相应的缓冲池槽存储了一个页面,但没有 PostgreSQL 进程正在访问该页面 (即, usage_count 大于或等于 1,但 refcount 为 0) 时,该缓冲区描述符的状态为unpinned。
在下图中 ,缓冲区描述符的状态由彩色框表示。

另外 ,脏页被表示为“X ”。例如,未固定的脏描述符由 X 表示。
缓冲区描述符的集合形成一个数组,在本文档中称为缓冲区描述符层。
当PostgreSQL服务器启动时,所有缓冲区描述符的状态都是空的。在 PostgreSQL 中,这些描述符包含一个称为 freelist 的链表(图 1.5)。
需要注意的是,PostgreSQL 中的空闲列表与 Oracle 中的空闲列表是完全不同的概念。
PostgreSQL 中的空闲列表只是空缓冲区描述符的链接列表。在 PostgreSQL 中,第 5.3.4 节中描述的自由空间映射与 Oracle 中的自由列表具有相同的用途。
图 1.5 缓冲区管理器初始状态。
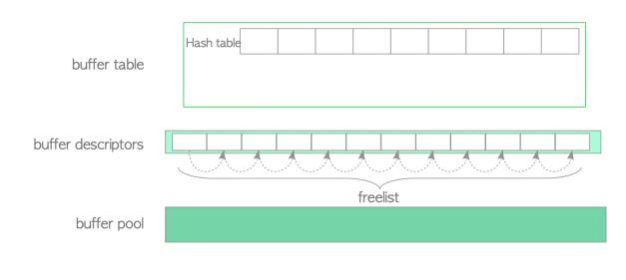
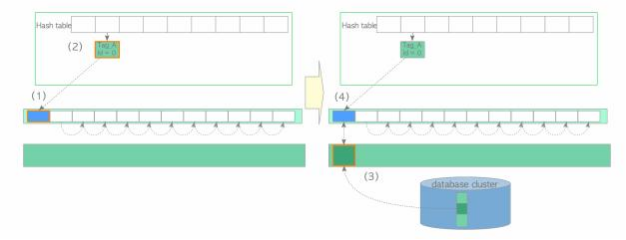
图 1.6 显示了第一页是如何加载的。
(1) 从空闲列表的顶部检索一个空描述符,并将其固定(即将其 refcount 和 use_count 加 1)。
(2) 在缓冲表中插入一个新条目,将第一页的tag映射到检索到的描述符的 buffer_id。
(3) 将新页从存储器加载到相应的缓冲池槽中。
(4) 将新页面的元数据保存到检索到的描述符中。
第二页和后续页面以类似的方式加载。第 4.2 节提供了更多详细信息。
从空闲列表中检索的描述符始终保存页面的元数据。换句话说,非空描述符一旦被使用就不会返回到空闲列表。但是,当发生以下情况之一时,相应的描述符会再次添加到空闲列表中,并将描 述符状态设置为“空 ”:
1. 表或索引被删除。
2. 数据库被删除。
3. 使用 VACUUM FULL 命令清理表或索引。
缓冲区描述符层包含一个无符号的 32 位整数变量,即 nextVictimBuffer。该变量用于第 4.4 节中描述的页面替换算法。
缓冲池是一个简单的数组,用于存储数据文件页,例如表和索引。缓冲池数组的索引称为 buffer_ids。
缓冲池槽大小为8 KB,等于页面的大小。因此,每个槽可以存储整个页。
缓冲区管理器使用许多锁来实现多种目的。本节描述了后续各节中的解释所必需的锁。
请注意 ,本节中描述的锁是缓冲区管理器同步机制的一部分。它们不涉及任何 SQL 语句或 SQL 选项。
Buf MappingLock保护整个缓冲表的数据完整性。 它是一种轻量级锁,可以在共享和独占模式下使用。当在缓冲表中搜索条目时,后端进程持有共享的Buf MappingLock。当插入或删除条目时,后端进程持有排他锁。
Buf MappingLock 被分成多个分区以减少缓冲表中的争用(默认为 128 个分区)。每个 Buf MappingLock分区保护对应的哈希桶槽的一部分。
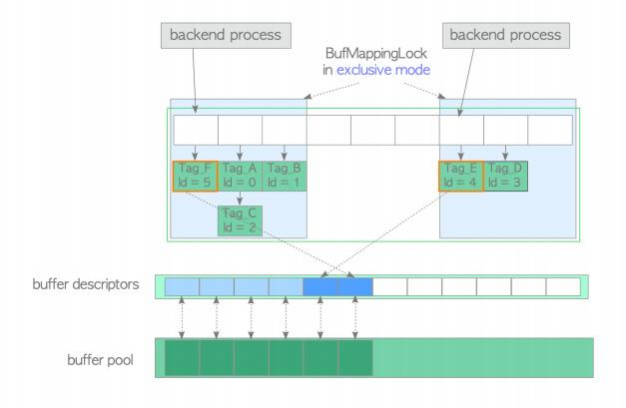
图1.7展示了Buf MappingLock分裂效果的典型例子。两个后端进程可以同时以独占模式持有各自的Buf MappingLock分区以插入新的数据条目。如果 Buf MappingLock 是单个系统范围的锁,则两个进程都必须等待另一个进程完成,具体取决于哪个进程先启动。
图 1.7 两个进程以独占方式同时获取Buf MappingLock的各自分区来插入新的数据条目。
缓冲表需要许多其他锁。例如,缓冲表内部使用自旋锁来删除条目。然而,省略了对这些其他锁的描述,因为它们在本文档中不是必需的。
在9.5或更早版本中,每个缓冲区描述符使用两个轻量级锁,content_lock和io_in_progress_lock,来控制对相应缓冲池槽中存储页面的访问。 当检查或更改其自身字段的值(即, usage_count、 refcount、flags) 时,将使用自旋锁(buf_hdr_lock)。
在 9.6 版本中,缓冲区访问方法得到了改进。io_in_progress_lock 和自旋锁 (buf_hdr_lock) 已被删除。9.6 及更高版本不使用这些锁,而是使用 CPU 原子操作来检查和更改它们的值。
content_lock 是一个典型的强制访问限制的锁。它可以在共享和独占模式下使用。
读取页面时,后端进程会获取存储该页面的缓冲区描述符的共享 content_lock(buffer pin)
执行以下操作之一时会获取独占 content_lock:
· 将行(即元组)插入存储页面或更改存储页面内元组的 t_xmin/t_xmax 字段。
· 物理删除元组或压缩存储页面上的可用空间。
· 冻结存储页面内的元组。
官方 README 文件提供了更多详细信息。
在版本 9.5 或更早版本中,io_in_progress 锁用于等待缓冲区上的 I/O 完成。 当 PostgreSQL 进程从存储加载页面数据或向存储写入页面数据时,该进程在访问存储时会获取相应描述符的独占 io_in_progress 锁。
当检查或更改标志或其他字段(例如 refcount 和 use_count)时,将使用自旋锁。下面给出两个自旋锁使用的具体例子:
(1) 固定缓冲区描述符:
· 1. 获取缓冲区描述符的自旋锁。
· 2. 将其refcount和usage_count的值增加1。
· 3. 释放自旋锁。
(2) 将脏位设置为“ 1 ”:
· 1. 获取缓冲区描述符的自旋锁。
· 2. 使用按位运算将脏位设置为“ 1 ”。
· 3. 释放自旋锁。
改变其他位以相同的方式执行。
本节介绍缓冲区管理器的工作原理。 当后端进程想要访问所需的页面时,它会调用 Read BufferExtended函数。
Read BufferExtended 函数的行为取决于三种逻辑情况。以下小节对每种情况进行了描述。此外,最后一小节描述了 PostgreSQL 时钟扫描页面替换算法。
首先,描述最简单的情况,其中所需的页面已经存储在缓冲池中。在这种情况下,缓冲区管理器执行以下步骤:
(1) 创建所需页面的buffer_tag(在本例中 , buffer_tag为'Tag_C')并使用哈希函数计算包含所创建的buffer_tag的关联条目的哈希桶槽位。
(2)以共享方式获取覆盖所获取的哈希桶槽位的Buf MappingLock分区(该锁将在步骤(5) 中释放)。
(3) 查找标签为“ Tag_C ”的条目 ,并从该条目中获取buffer_id。在此示例中 , buffer_id 为 2。
(4) 固定buffer_id 2 的缓冲区描述符,将描述符的refcount 和usage_count 加1。(第3.2 节描述了固定)。
(5) 释放Buf MappingLock。
(6) 访问buffer_id为2的缓冲池槽。
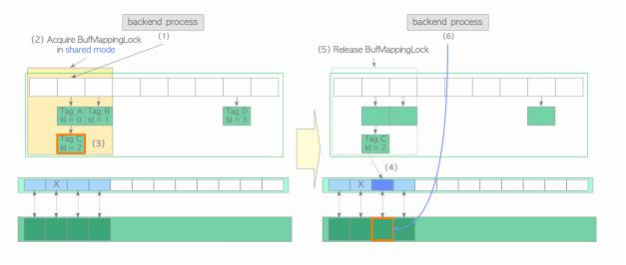
然后 , 当从缓冲池槽中的页面读取行时, PostgreSQL进程获取相应缓冲区描述符的共享 content_lock。 因此 ,缓冲池槽可以同时被多个进程读取。
当向页面插入(以及更新或删除)行时, Postgres 进程会获取相应缓冲区描述符的独占 content_lock。 (请注意 ,该页的脏位必须设置为“ 1 ”。)
访问页面后,相应缓冲区描述符的refcount值减1。
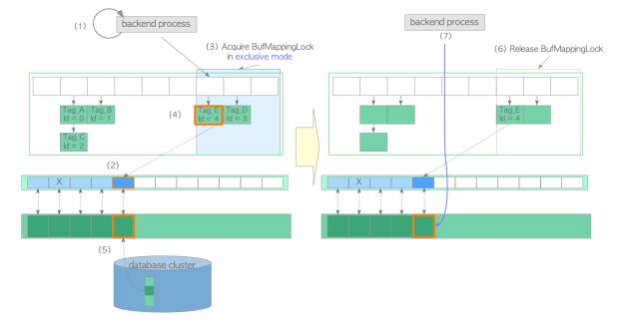
在第二种情况下,假设所需的页面不在缓冲池中,并且空闲列表具有空闲元素(空描述符)。在 这种情况下,缓冲区管理器执行以下步骤:
( 1)查找缓冲表(我们假设没有找到)。
。 1. 创建所需页面的buffer_tag(本例中buffer_tag为“ Tag_E ”)并计算哈希桶槽位。
。 2、以共享方式获取Buf MappingLock分区。
。 3. 查找缓冲表。 (根据假设没有找到。)
。 4. 释放Buf MappingLock。
(2) 从freelist中获取空缓冲区描述符,并pin它。本例中获取的描述符的buffer_id为4。
(3) 以独占方式获取Buf MappingLock分区。 (该锁将在步骤(6) 中释放。)
(4) 创建一个新的数据条目,其中包含 buffer_tag 'Tag_E' 和 buffer_id 4. 将创建的条目插入到 缓冲表中。
(5) 将所需的页数据从存储加载到buffer_id 4的缓冲池槽中,如下所示:
。 1、9.5及之前版本 ,获取对应描述符的独占io_in_progress_lock。
。 2. 将相应描述符的io_in_progress位设置为“ 1 ” ,以防止其他进程访问。
。 3. 将所需的页面数据从存储器加载到缓冲池槽。
。 4. 更改相应描述符的状态: io_in_progress 位设置为“0 ” ,有效位设置为“ 1 ”。
。 5. 在9.5或更早版本中 ,释放io_in_progress_lock。
(6) 释放Buf MappingLock。
(7) 访问buffer_id为4的缓冲池槽。
图 1.9 将页面从存储加载到空槽。
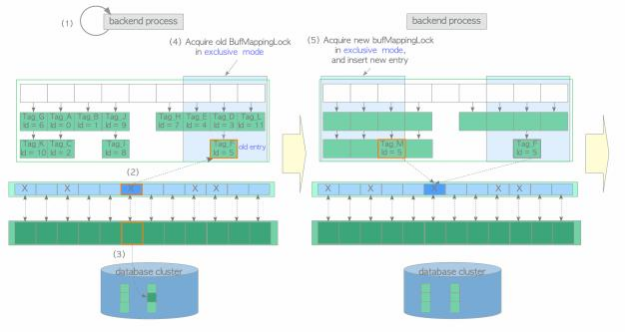
在这种情况下,假设所有缓冲池槽都被页面占用,但未存储所需的页面。缓冲区管理器执行以下步骤:
(1) 创建所需页面的buffer_tag并查找缓冲表。在此示例中,我们假设 buffer_tag 为 “ Tag_M ”(未找到所需页面)。
(2) 使用时钟扫描算法选择受害者缓冲池槽。从缓冲区表中获取包含受害者池槽的 buffer_id 的旧条目,并将受害者池槽固定在缓冲区描述符层中。在此示例中,受害者槽的 buffer_id 为 5, 旧条目为“ Tag_F, id =5 ”。 时钟扫描将在下一小节中描述。
(3) 如果受害者页面数据脏了,则刷新(写入和fsync) ;否则进行步骤(4)。
在用新数据覆盖之前,必须将脏页写入存储。刷新脏页的过程如下:
。 1. 获取buffer_id为5的描述符的共享content_lock和独占io_in_progress锁(在步骤6中释放)。
。 2、改变对应描述符的状态; io_in_progress 位设置为“ 1 ”,just_dirtied 位设置为“0 ”。
。 3、根据情况调用XLogFlush()函数 ,将WAL缓冲区上的WAL数据写入当前WAL段文件 (详细内容略 ,WAL和XLogFlush函数在第9章中介绍)。
。 4. 将受害者页面数据刷新到存储中。
。 5、改变对应描述符的状态; io_in_progress 位设置为“0 ” ,有效位设置为“ 1 ”。
。 6. 释放io_in_progress 和content_lock 锁。
(4) 以独占模式获取覆盖包含旧条目的槽的旧Buf MappingLock分区。
(5) 获取新的Buf MappingLock分区并将新条目插入缓冲表:
。 1. 创建由新的 buffer_tag“ Tag_M ”和受害者的 buffer_id 组成的新条目。
。 2. 获取新的 Buf MappingLock 分区 ,该分区覆盖包含独占模式下的新条目的槽。
。 3. 将新条目插入缓冲表。
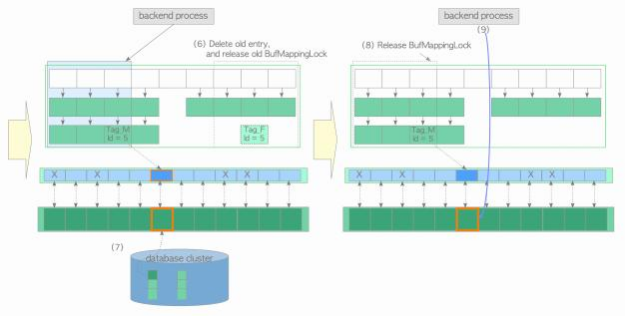
(6) 从缓冲表中删除旧条目 ,并释放旧的Buf MappingLock分区。
(7) 将所需的页面数据从存储器加载到牺牲缓冲槽中。然后,用buffer_id 5更新描述符的标志;脏位被设置为 0,其他位被初始化。
(8) 释放新的Buf MappingLock分区。
(9) 访问buffer_id为5的缓冲池槽。
本节的其余部分描述时钟扫描算法。该算法是NFU( NotFrequentlyUsed) 的变体,开销较低; 它有效地选择不常用的页面。
将缓冲区描述符想象成一个循环列表(图 1.12) 。 nextVictimBuffer 是一个无符号 32 位整数,始终指向缓冲区描述符之一并顺时针旋转。
算法的伪代码和描述如下
具体例子如图1. 12所示。缓冲区描述符显示为蓝色或青色框,框中的数字显示每个描述符的usage_count。(1) 获取nextVictimBuffer指向的候选缓冲区描述符。
(2) 如果候选缓冲区描述符未固定 ,则继续步骤(3)。否则,继续步骤(4)。
(3)如果候选描述符的usage_count为0 ,则选择该描述符对应的slot作为victim ,并执行步骤(5)。否则 ,将该描述符的usage_count减1并继续执行步骤(4)。
(4) 将 nextVictimBuffer 前进到下一个描述符(如果在末尾 ,则回绕)并返回到步骤 (1)。 重复此过程 ,直到找到受害者。
(5) 返回受害者的buffer_id。
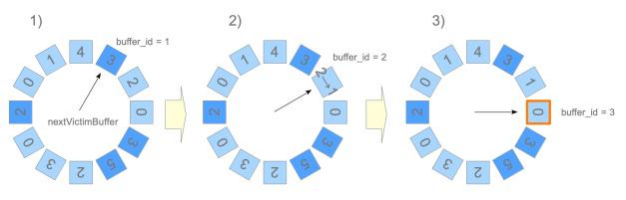
1. nextVictimBuffer 指向第一个描述符(buffer_id 1)。但是,该描述符会被跳过,因为它已被固定。
2. nextVictimBuffer 指向第二个描述符(buffer_id 2)。该描述符已取消固定 ,但其use_count 为 2。 因此, usage_count 减 1,并且 nextVictimBuffer 前进到第三个候选者。
3. nextVictimBuffer 指向第三个描述符(buffer_id 3)。该描述符已取消固定 ,并且其usage_count为0。 因此,这是本轮的受害者。
每当nextVictimBuffer扫描一个unpinned描述符时, 它的usage_count就会减1。 因此 , 如果缓冲池中存在unpinned描述符,该算法总是可以通过旋转nextVictimBuffer找到一个 usage_count为0的victim。
补充ORACLE LRU算法
当读取或写入大表时, PostgreSQL 使用环形缓冲区而不是缓冲池。环形缓冲区是一个小的临时缓冲区。 当满足以下任一条件时,环形缓冲区被分配给共享内存:
1. 批量阅读:
当扫描大小超过缓冲池大小(shared_buffers / 4) 四分之一的关系时。在本例中,环形缓冲区大小为 256 KB。
2. 批量写入:
当执行下面列出的 SQL 命令时。在本例中 ,环形缓冲区大小为 16 MB。
· COPY FROM command.
· CREATE TABLE AS command.
· CREATE MATERIALIZED VIEW or REFRESH MATERIALIZED VIEW command. · ALTER TABLE command.
3. Vacuum进程:
当 autovacuum 执行真空处理时。在本例中 ,环形缓冲区大小为 256 KB。
为什么是 256 KB?答案在缓冲区管理器源目录下的自述文件中进行了解释。
对于顺序扫描 ,使用 256 KB 环。 它足够小 ,可以放入 L2 缓存 ,这使得将页面从操作系统缓存传输到共享缓冲区缓存变得高效。更少通常就足够了 ,但环必须足够大 ,以容纳扫描中同时固定的所有页面。
除了替换受害者页面之外 ,检查指针和后台编写器还会将脏页面刷新到存储中。两个进程具有相同的功能 ,即刷新脏页,但它们具有不同的角色和行为。
检查点进程将检查点记录写入 WAL 段文件 ,并在检查点开始时刷新脏页。 9.7 节描述了检查点及其开始时间。
后台写入器的作用是减少检查点密集写入的影响。后台写入器继续一点一点地刷新脏页 ,对数据库活动的影响最小。默认情况下 ,后台写入器每 200 毫秒唤醒一次(由 bgwriter_delay 定义)并最多刷新 bgwriter_l ru_maxpages (默认为 100 页)。
为什么检查点与后台编写器分离?
在9. 1或更早的版本中,后台编写器定期进行检查点处理。在9.2版本中 ,检查点进程已与后台写入进程分离。 由于标题为“ Separating bgwriter and checkpointer ”的提案中描述了原因, 因此其中的句子如下所示。
目前(2011 年) bgwriter 进程执行后台写入、检查点和其他一些职责。这意味着我们无法在不停止后台写入的情况下执行最终检查点 fsync , 因此在一个进程中执行这两件事会对性能产生负面影响。此外 ,我们在 9.2 中的目标是用锁存器取代轮询循环以降低功耗。 bgwriter 循环的复杂性很高 ,似乎不太可能提出使用锁存器的干净方法。