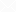客服微信

作者:刘晓峰
原文链接:http://www.tdpub.cn/Home/Blog/detail/action/preview/id/1304.html
讲解闩锁前我们先讲一个数据结构,也就是散列表(hash table ),下图为拉链法表示的散列表
这里不用关注散列表如何实现。我们关注其特性
讲完这个散列表,跟我们的闩锁有什么关系呢。
简单回顾一下oracle解析步骤
1. 加载到共享池- SQL 源代码被加载到 RAM 中进行解析。(“硬”解析步骤)
2. 语法分析- Oracle 分析语法以检查拼写错误的 SQL 关键字。
3. 语义解析- Oracle 验证字典中的所有表和列名称,并检查您是否有权查看数据。
4. 查询转换——Oracle 将把复杂的 SQL 转换为更简单、等效的形式,并酌情用物化视图替换聚合。在 Oracle 的早期版本中,必须为实体化视图重写设置query_rewrite=true 参数。
5. 优化- Oracle 然后根据您的模式统计信息(或者可能来自 10g 中的动态采样的统计信息)创建一个执行计划。Oracle 在此期间构建成本决策树,选择感知成本最低的路径。
6. 创建可执行文件- Oracle 使用本机文件调用构建可执行文件以服务 SQL 查询。
7. 获取行- Oracle 然后执行对数据文件的本地调用以检索行并将它们传递回调用程序。
当载入一条SQL文本的时候,如果库缓存中存在此SQL文本,表示是软解析,跳过上面的步骤1,如果库缓存中不存在,则表示是硬解析。
上面的步骤涉及到“存在”和“不存在”,所以是一个find 问题。此时hash表这个数据结构就有了用武之地。
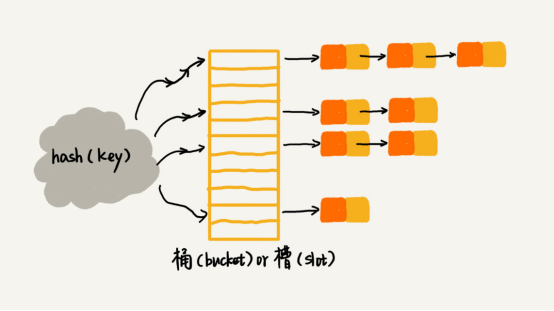
上图演化为:
Library cache:库缓存
Library cache latch,库缓存闩锁。
为什么需要这个闩锁呢。其实就是问共享池内存数据为什么需要被保护。也就是为什么内存数据会涉及到DML,如果是只读的,且不修改任何属性,也就不存在问题。
我们知道共享池用于缓存执行计划,数据字典缓存,SQL结果集和函数缓存,而缓存是有大小的,那些使用次数最少的缓存会从内存中老化退出。也就是针对上图的hash table,链表中的数据会被清除掉,而新的缓存又不断加入进来,所以这个链表会动态变化,修改链表的next值等于next的next的时候(其实是双向链表,所以还有last),如果这时还有会话去访问此链表,那么就会有问题。相当于读的时候,不能写,写的时候不能读。这不就是共享锁和排它锁吗?
但是Oracle的锁(lock),是用于保护磁盘数据,如果要处理高速内存数据,机制太慢,我们需要一个轻量级的内存锁-闩(lacth),要求获取和释放时间都极短,去保护内存的数据。Lock最主要是需要排队,而latch谁在一个时间片内抢到了就算谁的。
锁和闩分别对应视图v$lock和v$latch。除此之外我们还有互斥锁,pin锁,DDL锁,自定义锁。我们的hash table的数组上,每一个桶都有一个互斥锁(如果是保护lock的latch,则每个桶上还会有latch锁,比如enqueue hash chains),而pin锁会锁链表上的每一个节点。比如链表节点存储了执行计划,为了防止你正在使用执行计划EXECUTE SQL的时候,系统把此节点从链表删除.
我们主要关注桶前面的library cache latch锁
1. 愿意等待:如果获取不到闩,会话休眠,然后再次尝试。休眠时间称之为latch free wait time。library cache latches主要是愿意等待模式
2. 立即:如果当前进程获取不到闩,转而获取另一个闩,直到所有闩的都获取失败。
查询v$latch有如下字段
Addr 地址
latch# 等于v$latch_children.LATCH#
level# 级别
name 闩锁名称
hash 等于v$latch_children.HASH
gets 当前进程以愿意等待模式成功获取到闩锁的次数,如果闩自旋了1千次,才最终获取到闩锁,gets+1而不是+1001,
misses 当前进程以愿意等待模式尝试获取闩锁,当第一次尝试获取就失败了,则missed+1,并开始自旋
sleeps进程以愿意等待模式尝试获取闩锁,第一次获取失败,然后自旋,几千次循环都没成获取,则开始睡眠,sleeps+1。
immediate_gets 进程以立即模式获取闩锁,第一次尝试获取就获取成功,则immediate_gets+1
immediate_misses 立即模式获取失败
waiters_woken
waits_holding_latch
spin_gets 进程以愿意等待模式尝试获取闩锁,首次获取失败,然后开始自旋。如果在自旋里成功获取闩锁,spin_gets+1
wait_time 进程总等待时间,单位一般为微秒
参数增加顺序:
misses-> spin_gets自旋也没获取到-> sleeps
正常情况misses= spin_gets+sleeps
获取闩锁的顺序
1. 成功获取,然后释放
2. 获取失败->自旋->自旋超过spin_count,开始从CPU调度出去,开始休眠->休眠完毕唤醒,继续获取->(1获取又失败misses+1,->自旋->……睡眠时间上升)
->(2成功获取gets+1,然后释放)
为什么要“自旋”?
任务调度出CPU又调度回来涉及到上下文切换,而正常情况下闩锁获取释放速度很快,所以我在循环里一直获取,正常情况下循环几次就获取到了,如果循环个几千次,还是获取不到,才开始睡眠。这样平均等待时间比前者(指获取不到就开始睡眠)要快很多。
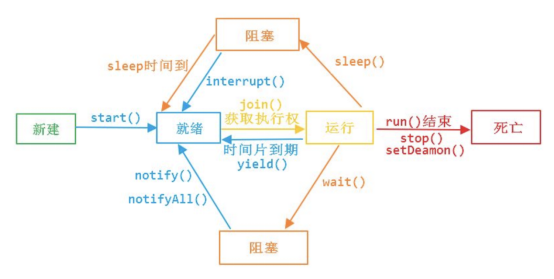
进程调度出CPU需要切换上下文,耗时较长,所以循环获取
因为这个库缓存闩锁比较少见,因此不去分析latch视图了,我们后面详细分析快块缓冲区闩锁现象,下面给出监测方法:这些SQL和会话都是有问题的
查询等待事件
SELECT sid, serial#, osuser, program
FROM v$session
WHERE sid IN (SELECT blocking_session
FROM v$session
WHERE event = 'latch: library cache');
查询高子游标计数和高版本sql
SELECT DISTINCT sql_id FROM v$sql_plan WHERE child_number >= 300 SELECT sql_id, version_count, sql_text FROM v$sqlarea WHERE version_count > 300;
查询高绑定变量sql
SELECT AVG(bind_count) avg_num_binds
FROM (SELECT sql_id, COUNT(*) bind_count
FROM v$sql_bind_capture
WHERE child_number = 0
GROUP BY sql_id);
SELECT *
FROM (SELECT sql_id, COUNT(*) bind_count
FROM v$sql_bind_capture
WHERE child_number = 0
GROUP BY sql_id)
HAVING bind_count >=300
分析这个词
Latch:闩锁
Cache:缓存,比如从磁盘读入数据,放入缓存,下一次直接读缓存而不是磁盘
buffers:缓冲区,比如有写缓冲区,写满了之后,再统一将缓冲区写磁盘,
chains:链
当我们遇到cache buffers就知道是块缓冲区缓存,而不是库缓存
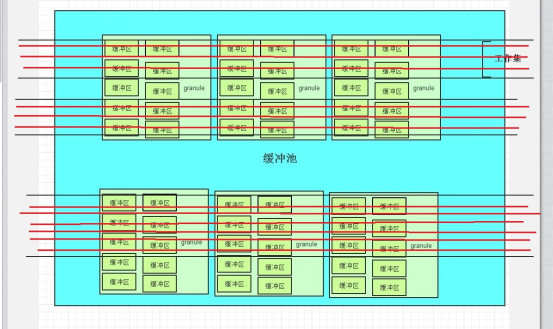
下图是块缓冲区的各个缓冲池示意图
来源:https://codeantenna.com/a/dBDXzPb3zQ
我们先接触一个词,granule(粒度),BLOCK是数据库最小I/O单元,那么granule就是共享池最小分配进程的连续虚拟内存单元,也是访问数据的最小工作单元。比如我们的自动内存管理,共享池和块缓冲区的大小会动态调整,那么增减的单元就是granule。查询v$sga_resize_ops可以看到最近的调整结果
上图可以看到:
一个缓冲池有多个granule,granule内部分为《缓冲区头部数组》和《缓冲区链》,一个工作集可以跨多个granule。这里《缓冲区头部数组》其实就是我们之前看到的X$BH
查询粒度大小,我本地是4M
select * from v$sgainfo where name='Granule Size';
查询共享池和块缓冲区大小
SELECT s.component
,s.current_size / 1024 / 1024 current_size
,s.granule_size / 1024 / 1024 granule_size
FROM v$sga_dynamic_components s
WHERE s.component in ('DEFAULT buffer cache','shared pool')
COMPONENT CURRENT_SIZE GRANULE_SIZE
1 shared pool 240 4
2 DEFAULT buffer cache 28 4
可以看到共享池240M,60个粒度,块缓冲区默认池28M,也就是7个粒度
查询块缓冲区粒度的链表
SELECT ge.grantype
,ct.component
,ge.granprev
,ge.grannum
,grannext
FROM x$ksmge ge
,x$kmgsct ct
WHERE ge.grantype != 6
AND ct.grantype = ge.grantype
and ct.component='DEFAULT buffer cache'
GRANTYPE COMPONENT GRANPREV GRANNUM GRANNEXT
1 9 DEFAULT buffer cache 0 63 64
2 9 DEFAULT buffer cache 63 64 65
3 9 DEFAULT buffer cache 64 65 66
4 9 DEFAULT buffer cache 65 66 67
5 9 DEFAULT buffer cache 66 67 68
6 9 DEFAULT buffer cache 67 68 69
7 9 DEFAULT buffer cache 68 69 0
GRANNEXT指向下一个粒度的指针,GRANNUM是当前指针,从上图可以看到按顺序排列,所以可以得出结论,我的块缓冲区没有动态调整过,当然因为我启用的是手动SGA内存管理。缓冲池内的所有的GRANULE双向链表串联起来组成大的缓冲池。
--查询所有内存组件的粒度
SELECT ct.component
,COUNT(1) * 4
FROM x$ksmge ge
,x$kmgsct ct
WHERE 1 = 1
AND ct.grantype = ge.grantype
GROUP BY ct.component
--查询当前大小
SELECT s.component
,s.current_size / 1024 / 1024 current_size
,s.granule_size / 1024 / 1024 granule_size
FROM v$sga_dynamic_components s
WHERE s.component in ('DEFAULT buffer cache','shared pool')
--查询当前块缓冲区详细信息
select * from v$buffer_pool;
我们的缓冲池里面的缓冲区个数是固定的,缓冲区链由工作集管理,当新的数据进入内存的时候,如何决定哪些缓冲区需要clear,LRU(Least recently used)算法就是最近最少被使用缓冲区应该被老化退出。
回到我们的工作集
SELECT k.cnum_set --工作集中缓存区数量
,k.set_latch --cache buffer latch地址
,k.cnum_repl --缓冲区数量总和
,k.nxt_repl--最多使用的缓冲区,缓冲区链的热端(链表头部)
,k.prv_repl--最少使用的缓冲区,缓冲区链的冷端(链表尾部)
,k.cold_hd --缓冲区头部链表冷热分界点
,K.NXT_REPLAX--备用链头部,备用链比主链少了刷新脏块,获取和释放pin,所以从备用链获取可老化的缓冲区比主链更快
--一般而言,备用链头部链接在k.prv_repl对应的主链的尾部
,K.PRV_REPLAX--备用链尾部
,k.addr--等于x$bh.set_ds 表示此工作集有多少缓冲区
FROM x$kcbwds k;
我们只关注主链,这个表的每一行就是一个工作集,由链表头部nxt_repl和链表尾部prv_repl决定的链表就是缓冲区头部链表,那么此链表的每一个节点就是代表一个个缓冲区。
缓冲区头部可以简单理解成缓冲区的指针,所以后面遇到缓冲区还是缓冲区头部,可以理解他们都是指代同一个东西,就是缓冲区。每个缓冲区内部里面有很多block。

上面的链表就是cache buffer lru chain 链表,每一个缓冲区上有一个TCH接触计数,这个TCH的修改机制比较复杂,这里不详细描述,所以我们简化一下,可以简单看成,链表左边的TCH较高,越往右越低,温度较低的缓冲区是从内存老化的优先选择对象。
(TCH计算逻辑并不是访问一次就+1,这里不详细讨论,只是大概表达意思)
而我们下面要讲到的cache buffer chain ,虽然节点还是一样的,都是缓冲区,不过他们能链接到一个链表上完全是因为hash 散列的结果,所以这个cache buffer chain链上的温度排列并不是左边的最高,右边的越低
现在我们有了一个LRU链表,决定哪些缓冲区需要老化,但是我们还需要前面讲到的hash table 结构去快速判断是物理读还是逻辑读。回想我们通过索引访问数据的过程,通过where条件对应的索引树,找到叶子节点对应的ROWID,ROWID是文件号,块号,块内行号组成的伪列,所以拿到ROWID就确定了是哪一个块,此次我们需要使用hash table,还是以上图举例
这里的key值简单等价为块号,传入的桶对应的链表就是缓冲区,也就是上图链表中的矩形节点。我们顺序读,读入一个BLOCK,然后通过散列函数,计算出它应该放入那个桶中,然后按某种规则加入到缓冲区链表中。
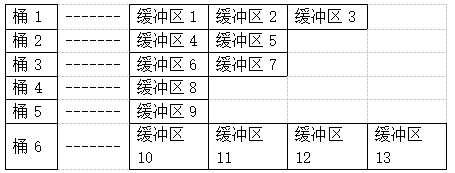
举例:
现在我们传入磁盘block号,通过hash table得到了桶1,那么接下来应该选择放入桶1的三个缓冲区中的一个,具体选择哪一个就是上一节讲到的LRU链, 现在我们把LRU链也画一下,假设我们有2个工作集
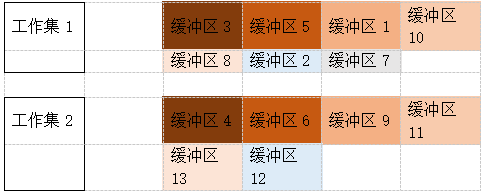
颜色越淡,表示越冷,因此备选缓冲区是2,我们需要修改缓冲区2的数据,回顾我们的库缓存latch,修改前必须要对其加锁,所以改造一下我们的缓冲区hash链
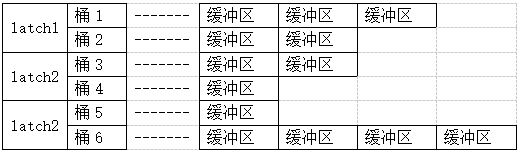
我们必须首先获取桶1和桶2对应的latch1,然后再去修改桶1的缓冲区链表,这个latch就是标题的latch:cache buffers chains 既然是我们熟悉的latch锁,回想一下
Misses,spin_gets,sleeps这些关键词,一旦我们有两个SQL访问的块位于同一个latch管辖的桶内,这两个SQL又都在大量进行buffer gets,他们都会争抢latch锁,最后造成此等待事件。
此时我们假如获取到了latch1,同时通过LRU链我们选择把数据放在缓冲区2中,先pin住缓冲区2,如果不能pin住,则需要等待,此时触发等待事件 buffer busy wats 成功获取pin之后释放闩锁,再缓存我们的数据(这里都不考虑一致性读情况),然后获取闩锁,解除pin,再解除latch锁,完成访问。(LRU链也发生了更新,所以LRU上也会有LATCH锁去控制,这里不详细讨论)
很多文章讲到这个等待事件,给出的解决方案是解决热点块现象,比如多个会话访问同一个块,不过热点块并不是决定因素,同一个buffer chain上的块+多会话+频繁访问才会出现。而buffer busy wait,才与热点块关系比较紧密。热点块以及块上TCH过高,只是说有可能有关系,我们现在来重现一下。
首先随便在latch链中找到一行数据(如果oracle能提供函数,传入块信息,返回latch信息,那么我就能自己造测试数据了)
SELECT addr FROM v$latch_children WHERE NAME = 'cache buffers chains' AND rownum = 1;
然后查一下这个buffer header 链上都有哪些块的数据
SELECT e.owner || '.' || e.segment_name segment_name
,e.file_id
,e.extent_id extent#
,x.dbablk
,x.dbablk - e.block_id + 1 block#
,x.tch
,l.child#
,l.gets
,l.misses
,l.sleeps
,l.wait_time / 1000000 / 3600
,l.latch#
,l.hash
FROM v$latch_children l
,x$bh x
,dba_extents e
WHERE 1 = 1
AND l.addr = '000000006BDE6660'
AND e.file_id = x.file#
AND x.hladdr = l.addr
AND x.dbablk BETWEEN e.block_id AND e.block_id + e.blocks - 1
ORDER BY x.tch DESC;
|
SEGMENT_NAME |
FILE_ID |
EXTENT# |
DBABLK |
BLOCK# |
TCH |
CHILD# |
GETS |
MISSES |
SLEEPS |
|
SYS.AQ$_SUBSCRIBER_LWM |
1 |
0 |
17432 |
1 |
4 |
1024 |
66047 |
0 |
0 |
|
SYS.C_OBJ# |
1 |
17 |
12264 |
105 |
0 |
1024 |
66047 |
0 |
0 |
|
SYS.OPTSTAT_SNAPSHOT$ |
1 |
20 |
118530 |
3 |
0 |
1024 |
66047 |
0 |
0 |
|
SYS.SYS_C003253 |
1 |
0 |
20016 |
1 |
1 |
1024 |
66047 |
0 |
0 |
第一行块号是1,因此简单查询第一行就行(反复执行此SQL你会发现TCH会持续增长)
select * from SYS.AQ$_SUBSCRIBER_LWM where rownum=1;
第二行是一个聚簇,与索引聚簇表有关,第4行是一个索引,这里我们没有函数去查询索引块对应的数据是哪一行,第三行是一个表,因此用第三行对应的表测试。
select * from dba_extents d where d.file_id=1 and d.extent_id=20;
|
OWNER |
SEGMENT_NAME |
PARTITION_NAME |
SEGMENT_TYPE |
TABLESPACE_NAME |
EXTENT_ID |
FILE_ID |
BLOCK_ID |
BYTES |
BLOCKS |
|
SYS |
OPTSTAT_SNAPSHOT$ |
|
TABLE |
SYSTEM |
20 |
1 |
118528 |
1048576 |
128 |
查询此表分配了128个块
尝试从block_id 118528开始,找3个块,一直访问此数据,但是并没有增加接触计数
SELECT ROWID
,dbms_rowid.rowid_block_number(ROWID)
FROM sys.optstat_snapshot$ s
WHERE dbms_rowid.rowid_block_number(ROWID) - 118528 <= 3 AND dbms_rowid.rowid_block_number(ROWID) - 118528 >= 0;
因此直接按ROWID排序,取前1000行数据
select * from (select * from sys.optstat_snapshot$ order by rowid ) where rownum<=1000;
因此改造这两个SQL,期望重现latch锁等待事件
窗口1:
--SELECT userenv('sid') FROM dual;--470
declare
cursor a_cur is
select * from SYS.AQ$_SUBSCRIBER_LWM where rownum=1;
begin
for i in 1..1000000 loop
for a_rec in a_cur loop
null;
end loop;
end loop;
end;
窗口2:
--SELECT userenv('sid') FROM dual; --467
declare
cursor a_cur is
select * from (select * from sys.optstat_snapshot$ order by rowid ) where rownum<=1000; begin for i in 1..10000 loop for a_rec in a_cur loop null; end loop; end loop; end;
执行后查看等待事件表
SELECT * FROM v$session_wait s WHERE s.sid IN (467, 470)
|
SID |
SEQ# |
EVENT |
P1TEXT |
P1 |
P1RAW |
|
467 |
1938 |
direct path write temp |
file number |
201 |
00000000000000C9 |
|
470 |
431 |
latch: cache buffers chains |
address |
1809474512 |
000000006BDA63D0 |
成功重现latch: cache buffers chains
查看此p1的值,并不是我们上图取出来的'000000006BDE6660'
如果我们代入000000006BDA63D0会发现出现的段是其它两个系统段,
而且按我们期望,取消467的查询,却并不能缓解470上的latch锁现象
当我反复执行上面的查询时候,我发现接触计数高的是这两个段
SYS.AQ$_SUBSCRIBER_LWM 和 SYS.C_OBJ# ,只能说这两个对象不能独立访问,因此我们去实际环境中重现此等待事件。
SELECT l.addr, e.owner || '.' || e.segment_name FROM v$latch_children l, x$bh x, dba_extents e WHERE 1 = 1 AND e.file_id = x.file# AND x.hladdr = l.addr AND x.dbablk BETWEEN e.block_id AND e.block_id + e.blocks - 1 AND e.segment_type = 'TABLE' AND e.tablespace_name <> 'SYSTEM'
2.随便取一个latch,将此latch地址传入
SELECT e.owner || '.' || e.segment_name
,segment_name
,l.addr
,e.extent_id extent#
,x.dbablk
,x.dbablk - e.block_id + 1 block#
,x.tch
,l.child#
,l.gets
,l.misses
,l.sleeps
,l.wait_time / 1000000 / 3600
,l.latch#
,l.hash
FROM v$latch_children l
,x$bh x
,dba_extents e
WHERE l.addr in ('0000001934656D68')
AND e.file_id = x.file#
AND x.hladdr = l.addr
AND x.dbablk BETWEEN e.block_id AND e.block_id + e.blocks - 1
|
SEGMENT_NAME |
DBABLK |
|
MTL_SYSTEM_ITEMS_B |
3219221 |
|
PO_REQUISITION_LINES_ALL |
1738115 |
SELECT ROWID
,dbms_rowid.rowid_block_number(ROWID)
FROM MTL_SYSTEM_ITEMS_B s
WHERE dbms_rowid.rowid_block_number(ROWID) = 3219221;
SELECT ROWID
,dbms_rowid.rowid_block_number(ROWID)
FROM PO_REQUISITION_LINES_ALL s
WHERE dbms_rowid.rowid_block_number(ROWID) =1738115
--2266
DECLARE
CURSOR a_cur IS
SELECT *
FROM po_requisition_lines_all msi
WHERE ROWID IN ('AAAdlDAIbAAGoWDAAA',
'AAAdlDAIbAAGoWDAAB',
'AAAdlDAIbAAGoWDAAD',
'AAAdlDAIbAAGoWDAAC',
'AAAdlDAIbAAGoWDAAG',
'AAAdlDAIbAAGoWDAAF',
'AAAdlDAIbAAGoWDAAE',
'AAAdlDAIbAAGoWDAAI',
'AAAdlDAIbAAGoWDAAH',
'AAAdlDAIbAAGoWDAAK',
'AAAdlDAIbAAGoWDAAJ',
'AAAdlDAIbAAGoWDAAM',
'AAAdlDAIbAAGoWDAAL');
BEGIN
for i in 1..100000 loop
FOR a_rec IN a_cur LOOP
NULL;
END LOOP;
end loop;
END;
--4045
DECLARE
CURSOR a_cur IS
SELECT *
FROM mtl_system_items_b msi
WHERE ROWID IN ('AAQ54NAKNAAMR8VAAA',
'AAQ54NAKNAAMR8VAAC',
'AAQ54NAKNAAMR8VAAE',
'AAQ54NAKNAAMR8VAAG',
'AAQ54NAKNAAMR8VAAI',
'AAQ54NAKNAAMR8VAAK',
'AAQ54NAKNAAMR8VAAM',
'AAQ54NAKNAAMR8VAAO');
BEGIN
FOR i IN 1 .. 100000 LOOP
FOR a_rec IN a_cur LOOP
NULL;
END LOOP;
END LOOP;
END;
select * from v$session_wait s where s.sid in (4045,2266);
|
SID |
EVENT |
P1RAW |
|
2266 |
latch: shared pool |
60292678 |
|
4045 |
latch: shared pool |
00000000602922B8 |
没测试出来块缓冲区上的latch锁,却测试出来 latch: shared pool
共享池闩锁的争用是由于共享池容量不足、未共享 SQL 或数据字典的大量使用,
查询硬解析
select * from V$SESS_TIME_MODEL s where s.SID in (4045,2266) order by value desc;
硬解析花费时间并不严重,所以这个等待事件可能是我第一次装载此SQL,同时绑定变量过多导致,再次重复执行
|
SID |
EVENT |
P1 |
|
2266 |
SQL*Net message from client |
1952673792 |
|
4045 |
latch free |
107898301512 |
出现了latch free,这个包括了所有的闩锁现象,如果我们对此会话开启了跟踪,并打开原始trace文件,搜索latch free

搜索此number号
select * from v$latchname l where l.latch#=228
LATCH# NAME DISPLAY_NAME HASH CON_ID
1 228 cache buffers chains cache buffers chains 3563305585 0
就显示为实际的latch锁。
根据我们前面的判断,如果停掉2266会话的查询,而是单独查询4045,则不会出现跟buffer cache有关的闩锁,此时我们重新按12345的步骤测试一下,唯一的区别是不执行2266的查询,等待事件结果如下:
|
SID |
EVENT |
P1 |
|
2266 |
SQL*Net message from client |
1952673792 |
|
4045 |
SQL*Net message from client |
1952673792 |
符合我们的预测
回顾一下它的原理,我们有多个进程正在访问同一个buffer cache chain 上的缓冲区,一个获取到了,另一个就不得不等待。所以核心就是减少额外的buffer gets.
如何减少:
1. 避免循环中重复读取相同的块,而且循环本身速度较快的话,闩锁现象越严重
2. 检查索引效率,避免出现索引全扫描或者大段的索引范围扫描,本不需要扫描额外的buffer,由于糟糕的索引或者执行计划,额外扫描了这些block
3. 避免全表扫描,不过oracle有机制控制,读大表的时候会避免更新TCH,我们期望这些大表不会污染我们的块缓冲区(可以放入回收池),一趟全表扫描并不可怕,因为我们的等待来源于逻辑读,全表扫描第一次全是物理读
如果你不能减小buffer gets,也就是说就是要这么频繁访问,那么第二步就是直接路径读,直接路径读不在赘述
如果你也不能采用直接路径读,那么我们只能从降低争用入手
1. 如果争用发生在同一个块的不同行,尝试使用反向键,防止同时访问同一个块
2. 因为latch散列只与块属性有关,所以你要么分时间段执行这两个SQL,要么增大块缓冲区,并期望能散列到别的latch上。
3. 由2可知,对争用比较严重的段采用create as select ,期望生成新的BLOCK_ID并散列到不同的LATCH上(未测试)